- +1-315-215-1633
- sales@thebrainyinsights.com

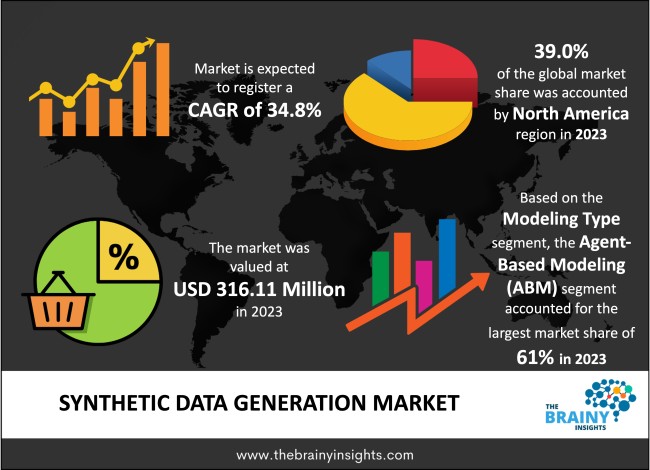
The global synthetic data generation market was valued at USD 316.11 Million in 2023 and is anticipated to grow at a CAGR of 34.8% from 2024 to 2033. Generating synthetic data involves producing artificial data sets that resemble real-time information, including statistical properties, patterns and associations. This technique can be utilized as a substitute or supplement for actual data in various applications where access to genuine inputs is restricted, expensive or poses privacy issues. Synthetic data creation entails replicating authentic datasets characteristics and statistical attributes while providing several advantages driven by diverse factors. Simulating real-life scenarios without acquiring extensive amounts of labelled raw materials offers organizations an economical, time-saving solution, overcoming privacy worries since created data points do not hold sensitive details. Additionally, allowing scalability customization options alongside diversifying possibilities empowers businesses to simulate differing edge cases easily.
The method of synthetic data generation has emerged as a crucial aspect within machine learning and data science technology. The synthetic data generation can bring revolutionary changes across multiple domains, including healthcare, finance, and cybersecurity. Synthetic data generation is a fundamental solution for addressing challenges related to diversity, privacy protection, and scarcity associated with datasets. Synthetic data generation involves producing artificial data that imitates the statistical traits and trends of actual information, all while obscuring identifiable or sensitive details. This innovative approach provides a practical solution for overcoming obstacles posed by scarce resources of accessible information sources; it helps create algorithms and models required for achievement through evidence-based initiatives. By utilizing advanced techniques from machine learning, statistics, and computer science domains, synthetic data creation aims to simulate genuine datasets' intricacies, enabling comprehensive analysis and stimulating discoveries within this field.
Get an overview of this study by requesting a free sample
Data Scarcity and Quality - The demand for high-quality training data has increased significantly with the rise of data-driven technologies such as artificial intelligence (AI), machine learning (ML), and the Internet of Things (IoT). However, many organizations still need help to acquire labelled data for model training and validation due to scarcity in niche domains or emerging markets. This aspect creates obstacles that hinder the development and deployment of AI-driven solutions. Synthetic data generation provides an appealing solution by augmenting existing datasets or generating new ones that capture underlying patterns and characteristics unique to a target domain. With advanced generative models, simulation techniques can bridge this gap between limited availability while simultaneously meeting requirements of core algorithms employed within AI/ML technology; innovation accelerated thanks to its ability, resulting in time-to-market reduction overall.
Lack of Standardization – The need for standard procedures and metrics for synthetic data production is a major hurdle that hampers its use across various platforms. Unlike traditional datasets evaluated on precise measures like accuracy, precision, or recall, the authenticity and utility of synthetic information have no universally accepted criteria to evaluate them correctly. Consequently, companies face significant challenges while assessing the quality and applicability of synthesized data in specific cases or applications. Establishing trust amongst stakeholders regarding such solutions requires standardized benchmarks with rigorous evaluation protocols augmented by stringent quality assurance mechanisms essential for sound decision-making capabilities within organizations seeking optimal results from this technology's deployment at scale.
Demand Across Industries - Synthetic data generation has various applications in various industries, each with unique needs and functions. In the healthcare industry, synthetic data is utilized to train medical imaging algorithms, simulate patient information for clinical research purposes, and create artificial electronic health records (EHRs) for investigations. For automotive and autonomous driving sectors, synthetic data allows diverse scenarios, such as simulated conditions, that help optimize perception systems appropriately under hazardous situations. Back-testing trading strategies using fake money plus simulating market trends, amongst others, are notable uses of it within finance institutions. In contrast, the retail industry exploits this technique mainly for demand forecasting activities along with customer segmentation & personalized recommendation engines, among other things, to become feasible because versatility accompanies every application. The scalability and versatility of synthetic data are the factors prompting its adoption across industries, ultimately fueling the remarkable market growth over the years.
The regions analyzed for the market include North America, Europe, South America, Asia Pacific, the Middle East, and Africa. North America region emerged as the most prominent global Synthetic data generation market, with a 39.0% market revenue share in 2023. A wide range of industries dominate North America, including technology, healthcare, finance, and automotive. These verticals have a common thread: an increasing need for synthetic data solutions. Synthetic data has various applications across the spectrum, from autonomous vehicle AI algorithm training to medical research by simulating patient information. This trend drives market expansion and widespread adoption in this region. The advanced technological infrastructure in North America includes advanced hardware, software and cloud computing resources that provide numerous benefits. With access to cutting-edge computer technologies, synthetic data generation solutions can be developed and deployed quickly at a scale previously unseen. This technology accelerates innovation and enables organizations to expand their operations with ease. The regional market players also engage in various market strategies such as product innovation, product differentiation, mergers, acquisitions, partnerships, and strategic alliances to maintain their competitive edge.
North America Region Synthetic Data Generation Market Share in 2022- 39.0%
www.thebrainyinsights.com
Check the geographical analysis of this market by requesting a free sample
The modeling type segment includes Direct modeling, and agent-based modeling (ABM). The agent-based modeling (ABM) segment dominated, with a market share of around 61% in 2023. ABM provides a detailed model of behaviors, interactions, and decision-making processes by providing a granular representation of individual agents, entities, or objects within the simulated environment. The autonomy and heterogeneity of these individuals enable ABM to simulate complex systems with diverse populations, dynamics, and emergent properties. With the help of ABM, systems can be modelled dynamically and adaptively. This means that agents can evolve, interact with their environment in response to changing conditions or external factors, and adjust themselves towards stimuli when needed. The dynamic nature of this methodology allows for simulations dealing with real-world scenarios involving contingencies and uncertainties, which is ideal for exploring complex phenomena such as scenario analysis and decision support purposes.
The type segment includes fully synthetic data, partially synthetic data, and hybrid synthetic data. The fully synthetic data segment dominated, with a market share of around 40% in 2023. Organizations can minimize privacy and security concerns linked with actual data by deploying completely synthetic data. As it lacks any sensitive or identifiable information, generating artificial data empowers organizations to abide by regulations governing the protection of personal information while securing confidential details from getting compromised. Fully synthetic data offers versatility in creating varied and illustrative datasets for training, testing, and validation. By simulating different scenarios, rare occurrences, and abnormalities, fully synthetic data empowers companies to investigate all potential outcomes comprehensively, ultimately enhancing machine learning models' resilience and universal application.
The application segment includes data protection, data sharing, predictive analytics, natural language processing, computer vision algorithms, and others. The natural language processing segment dominated, with a market share of around 36% in 2023. Computers can now comprehend, interpret and produce human speech thanks to Natural Language Processing (NLP). This aspect has transformed communication, knowledge extraction and information retrieval. The creation of Synthetic data presents a scalable solution for generating text that imitates the depth of language expression by humans. Diverse patterns of linguistics semantics within varying contexts are simulated through synthetic text data, which strengthens NLP models, leading to more robust applications like sentiment analysis, chatbots or language translation tools. As industries increasingly demand these solutions from NLP technology across all fields, there is likely an exponential surge expected in popularity, driving growth within the global synthetic data generation market share due to high-quality training requirements with readily available effective solutions at scale.
The industry segment is bifurcated into BFSI, healthcare, transportation & logistics, IT & telecommunication, retail & e-commerce, consumer electronics and others. The healthcare segment dominated, with a market share of around 38% in 2023. Advancements in artificial intelligence (AI), precision medicine, and digital health technologies are bringing about a paradigm shift in the healthcare industry. As such, synthetic data generation is gaining popularity as an innovative solution for organizations that want to leverage data for clinical research, drug development, and patient care. With this approach, generating realistic patient datasets that accurately represent diverse populations and complexities can enable quicker medical research outcomes and the deployment and optimization of treatment plans, leading to better chances of improved results with patients' wellbeing at the forefront. Additionally, training AI algorithms on synthesized data allow practitioners to engage with disease diagnosis and some breakthroughs while safeguarding their clients' privacy or information security.
| Attribute | Description |
|---|---|
| Market Size | Revenue (USD Million) |
| Market size value in 2023 | USD 316.11 Million |
| Market size value in 2033 | USD 6,262.27 Million |
| CAGR (2024 to 2033) | 34.8% |
| Historical data | 2020-2022 |
| Base Year | 2023 |
| Forecast | 2024-2033 |
| Region | The regions analyzed for the market are Asia Pacific, Europe, South America, North America, and Middle East & Africa. Furthermore, the regions are further analyzed at the country level. |
| Segments | Application, Modeling Type, Type, Industry |
As per The Brainy Insights, the size of the global synthetic data generation market was valued at 316.11 million in 2023 to USD 6,262.27 million by 2033.
The global synthetic data generation market is growing at a CAGR of 34.8% during the forecast period 2024-2033.
North America region became the largest market for synthetic data generation.
The rising adoption of synthetic data across the industries is driving the market's growth.
This study forecasts revenue at global, regional, and country levels from 2020 to 2033. The Brainy Insights has segmented the global synthetic data generation market based on below-mentioned segments:
Global Synthetic Data Generation Market by Type:
Global Synthetic Data Generation Market by Modeling Type:
Global Synthetic Data Generation Market by Industry:
Global Synthetic Data Generation Market by Application:
Global Synthetic Data Generation Market by Region:
Research has its special purpose to undertake marketing efficiently. In this competitive scenario, businesses need information across all industry verticals; the information about customer wants, market demand, competition, industry trends, distribution channels etc. This information needs to be updated regularly because businesses operate in a dynamic environment. Our organization, The Brainy Insights incorporates scientific and systematic research procedures in order to get proper market insights and industry analysis for overall business success. The analysis consists of studying the market from a miniscule level wherein we implement statistical tools which helps us in examining the data with accuracy and precision.
Our research reports feature both; quantitative and qualitative aspects for any market. Qualitative information for any market research process are fundamental because they reveal the customer needs and wants, usage and consumption for any product/service related to a specific industry. This in turn aids the marketers/investors in knowing certain perceptions of the customers. Qualitative research can enlighten about the different product concepts and designs along with unique service offering that in turn, helps define marketing problems and generate opportunities. On the other hand, quantitative research engages with the data collection process through interviews, e-mail interactions, surveys and pilot studies. Quantitative aspects for the market research are useful to validate the hypotheses generated during qualitative research method, explore empirical patterns in the data with the help of statistical tools, and finally make the market estimations.
The Brainy Insights offers comprehensive research and analysis, based on a wide assortment of factual insights gained through interviews with CXOs and global experts and secondary data from reliable sources. Our analysts and industry specialist assume vital roles in building up statistical tools and analysis models, which are used to analyse the data and arrive at accurate insights with exceedingly informative research discoveries. The data provided by our organization have proven precious to a diverse range of companies, facilitating them to address issues such as determining which products/services are the most appealing, whether or not customers use the product in the manner anticipated, the purchasing intentions of the market and many others.
Our research methodology encompasses an idyllic combination of primary and secondary initiatives. Key phases involved in this process are listed below:
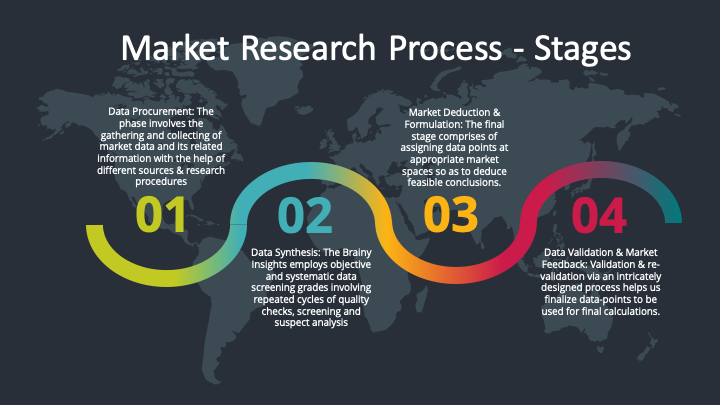
The phase involves the gathering and collecting of market data and its related information with the help of different sources & research procedures.
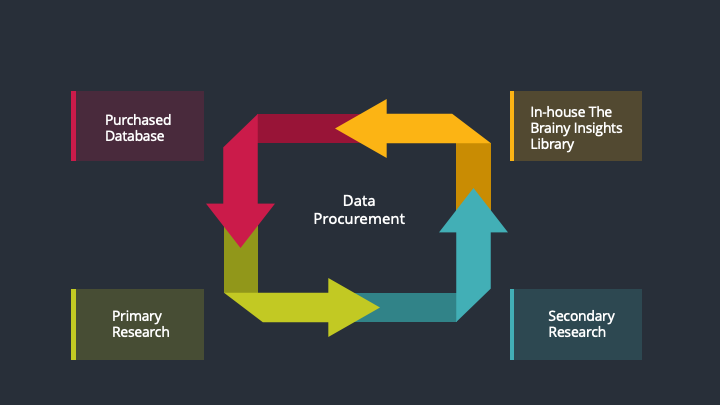
The data procurement stage involves in data gathering and collecting through various data sources.
This stage involves in extensive research. These data sources includes:
Purchased Database: Purchased databases play a crucial role in estimating the market sizes irrespective of the domain. Our purchased database includes:
Primary Research: The Brainy Insights interacts with leading companies and experts of the concerned domain to develop the analyst team’s market understanding and expertise. It improves and substantiates every single data presented in the market reports. Primary research mainly involves in telephonic interviews, E-mail interactions and face-to-face interviews with the raw material providers, manufacturers/producers, distributors, & independent consultants. The interviews that we conduct provides valuable data on market size and industry growth trends prevailing in the market. Our organization also conducts surveys with the various industry experts in order to gain overall insights of the industry/market. For instance, in healthcare industry we conduct surveys with the pharmacists, doctors, surgeons and nurses in order to gain insights and key information of a medical product/device/equipment which the customers are going to usage. Surveys are conducted in the form of questionnaire designed by our own analyst team. Surveys plays an important role in primary research because surveys helps us to identify the key target audiences of the market. Additionally, surveys helps to identify the key target audience engaged with the market. Our survey team conducts the survey by targeting the key audience, thus gaining insights from them. Based on the perspectives of the customers, this information is utilized to formulate market strategies. Moreover, market surveys helps us to understand the current competitive situation of the industry. To be precise, our survey process typically involve with the 360 analysis of the market. This analytical process begins by identifying the prospective customers for a product or service related to the market/industry to obtain data on how a product/service could fit into customers’ lives.

Secondary Research: The secondary data sources includes information published by the on-profit organizations such as World bank, WHO, company fillings, investor presentations, annual reports, national government documents, statistical databases, blogs, articles, white papers and others. From the annual report, we analyse a company’s revenue to understand the key segment and market share of that organization in a particular region. We analyse the company websites and adopt the product mapping technique which is important for deriving the segment revenue. In the product mapping method, we select and categorize the products offered by the companies catering to domain specific market, deduce the product revenue for each of the companies so as to get overall estimation of the market size. We also source data and analyses trends based on information received from supply side and demand side intermediaries in the value chain. The supply side denotes the data gathered from supplier, distributor, wholesaler and the demand side illustrates the data gathered from the end customers for respective market domain.
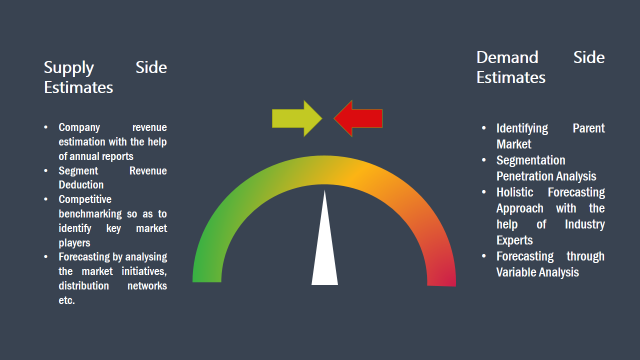
The supply side for a domain specific market is analysed by:
The demand side for the market is estimated through:
In-house Library: Apart from these third-party sources, we have our in-house library of qualitative and quantitative information. Our in-house database includes market data for various industry and domains. These data are updated on regular basis as per the changing market scenario. Our library includes, historic databases, internal audit reports and archives.
Sometimes there are instances where there is no metadata or raw data available for any domain specific market. For those cases, we use our expertise to forecast and estimate the market size in order to generate comprehensive data sets. Our analyst team adopt a robust research technique in order to produce the estimates:
Data Synthesis: This stage involves the analysis & mapping of all the information obtained from the previous step. It also involves in scrutinizing the data for any discrepancy observed while data gathering related to the market. The data is collected with consideration to the heterogeneity of sources. Robust scientific techniques are in place for synthesizing disparate data sets and provide the essential contextual information that can orient market strategies. The Brainy Insights has extensive experience in data synthesis where the data passes through various stages:

Market Deduction & Formulation: The final stage comprises of assigning data points at appropriate market spaces so as to deduce feasible conclusions. Analyst perspective & subject matter expert based holistic form of market sizing coupled with industry analysis also plays a crucial role in this stage.
This stage involves in finalization of the market size and numbers that we have collected from data integration step. With data interpolation, it is made sure that there is no gap in the market data. Successful trend analysis is done by our analysts using extrapolation techniques, which provide the best possible forecasts for the market.
Data Validation & Market Feedback: Validation is the most important step in the process. Validation & re-validation via an intricately designed process helps us finalize data-points to be used for final calculations.
The Brainy Insights interacts with leading companies and experts of the concerned domain to develop the analyst team’s market understanding and expertise. It improves and substantiates every single data presented in the market reports. The data validation interview and discussion panels are typically composed of the most experienced industry members. The participants include, however, are not limited to:
Moreover, we always validate our data and findings through primary respondents from all the major regions we are working on.


















































Free Customization
Fortune 500 Clients
Free Yearly Update On Purchase Of Multi/Corporate License
Companies Served Till Date